Agent Monitoring for .NET Apps
Agent Monitoring for .NET Apps

We launched agent monitoring earlier this year, allowing our users to instrument LLM usage and tool calls in their applications. However, we only had Agent Monitoring support for Python and JavaScript. We’ve been working on creating an Agent Monitoring SDK for .NET — specifically for Microsoft.Extensions.AI.Abstractions.
Introducing Sentry.Extensions.AI
Sentry.Extensions.AI is our drop-in instrumentation layer for .NET LLM packages that are based on Microsoft.Extensions.AI.Abstractions. You can instrument your LLM usage including:
LLM calls
Inputs and outputs
Token count
Model name
Tool calls input/output
Issues related to the LLM call
Total cost
All of this is available to see in Sentry as spans and events, so you can correlate AI behaviour with the rest of your application: HTTP requests, background jobs, database queries, and more.
What is Microsoft.Extensions.AI.Abstractions?
Microsoft.Extensions.AI.Abstractions?The AI.Abstractions package is a low-level contract layer for many other libraries. It contains pure interfaces and data models for generative AI in .NET. It is intended for other libraries to implement. It has minimal dependencies so it can be the base for this ecosystem of libraries.
This is not to be confused with Microsoft.Extensions.AI, which includes utilities such as ChatClientBuilder, and built-in capabilities such as logging and tool invocation. The relationship between the abstraction package and Microsoft.Extensions.AI are very similar to the relationship between Microsoft.Extensions.Logging and its abstraction package.
Building our agent monitoring around Microsoft.Extensions.AI.Abstractions allow our users to use any LLM library they want, as long as they implement IChatClient from the abstractions package. For example, our ASP.NET Core sample project uses Microsoft.Extensions.AI.OpenAI , which provides us with IChatClient implementation with OpenAI APIs. One can just as easily swap out which LLM it is using by using a different library with IChatClient implementation.
How it works
Sentry.Extensions.AI works by wrapping your existing IChatClient and tools, so that every LLM call and tool invocation is automatically instrumented without changing your application logic.
In code, it looks roughly like this:
using Microsoft.Extensions.AI;
var openAiClient = new OpenAI.Chat.ChatClient("gpt-4o-mini", openAiApiKey)
.AsIChatClient()
.AddSentry(options =>
{
// AI-specific settings
options.Experimental.RecordInputs = true;
options.Experimental.RecordOutputs = true;
});
var client = new ChatClientBuilder(openAiClient)
.UseFunctionInvocation()
.Build();
var options = new ChatOptions
{
// Tools the LLM can call
Tools = [ /* ... tool definitions ... */ ]
}.AddSentryToolInstrumentation();
var response = await client.GetResponseAsync(
"Please help me with the following tasks...",
options);AddSentry wraps the OpenAI IChatClient, and AddSentryToolInstrumentation instruments tool calls. We intercept requests and responses, measure how long operations take, capture token usage and errors, and then pass everything through to the underlying client so the behaviour of your app doesn’t change.
Most of the work in this library was about doing that as transparently and cheaply as possible, while still handling tricky cases like streaming responses and multi-step tool-call loops.
Handling streaming responses without breaking error handling
One of the trickiest parts was instrumenting IChatClient.GetStreamingResponseAsync, which returns an IAsyncEnumerable<ChatResponseUpdate>. I wanted to:
Wrap the streaming loop with Sentry spans
Keep overhead minimal
Catch any exception thrown while fetching the next token, record it, and still re-throw it to the caller
But C# doesn’t let you yield return from inside a try/catch that needs to cover MoveNextAsync, and using foreach would implicitly wrap MoveNextAsync and yield return together.
The solution was to work with the async enumerator directly and separate the logic between advancing the stream and yielding the value:
public override async IAsyncEnumerable<ChatResponseUpdate> GetStreamingResponseAsync(
IEnumerable<ChatMessage> messages,
ChatOptions? options = null,
[EnumeratorCancellation] CancellationToken cancellationToken = default)
{
// Start spans and do any request enrichment here...
// Get the inner async enumerator
await using var inner = _innerClient
.GetStreamingResponseAsync(messages, options, cancellationToken)
.GetAsyncEnumerator(cancellationToken);
var allUpdates = new List<ChatResponseUpdate>();
while (true)
{
ChatResponseUpdate? current;
try
{
var hasNext = await inner.MoveNextAsync();
if (!hasNext)
{
// Finalize spans using the collected updates, then exit
// e.g. EnrichWithStreamingResponses(spans, allUpdates);
yield break;
}
current = inner.Current;
allUpdates.Add(current);
}
catch (Exception ex)
{
// Record the exception on the spans, then rethrow to user
throw;
}
// Yield outside the try/catch so the compiler is happy
yield return current;
}
}By calling MoveNextAsync() inside the try/catch and doing yield return afterwards, we can:
Preserve the original streaming behavior
Capture any exceptions thrown by the provider’s enumerator
Enrich and finish our spans once the stream ends or fails
The result is full visibility into streaming responses with essentially no extra overhead for the caller.
Capturing the whole tool-call loop in a single span
Another challenge was capturing one span that represents the entire “LLM + tools” loop, not just individual model calls or tool invocations. In the screenshot below, you can see that one span is a parent of all these other spans. This is what we call an agent span.
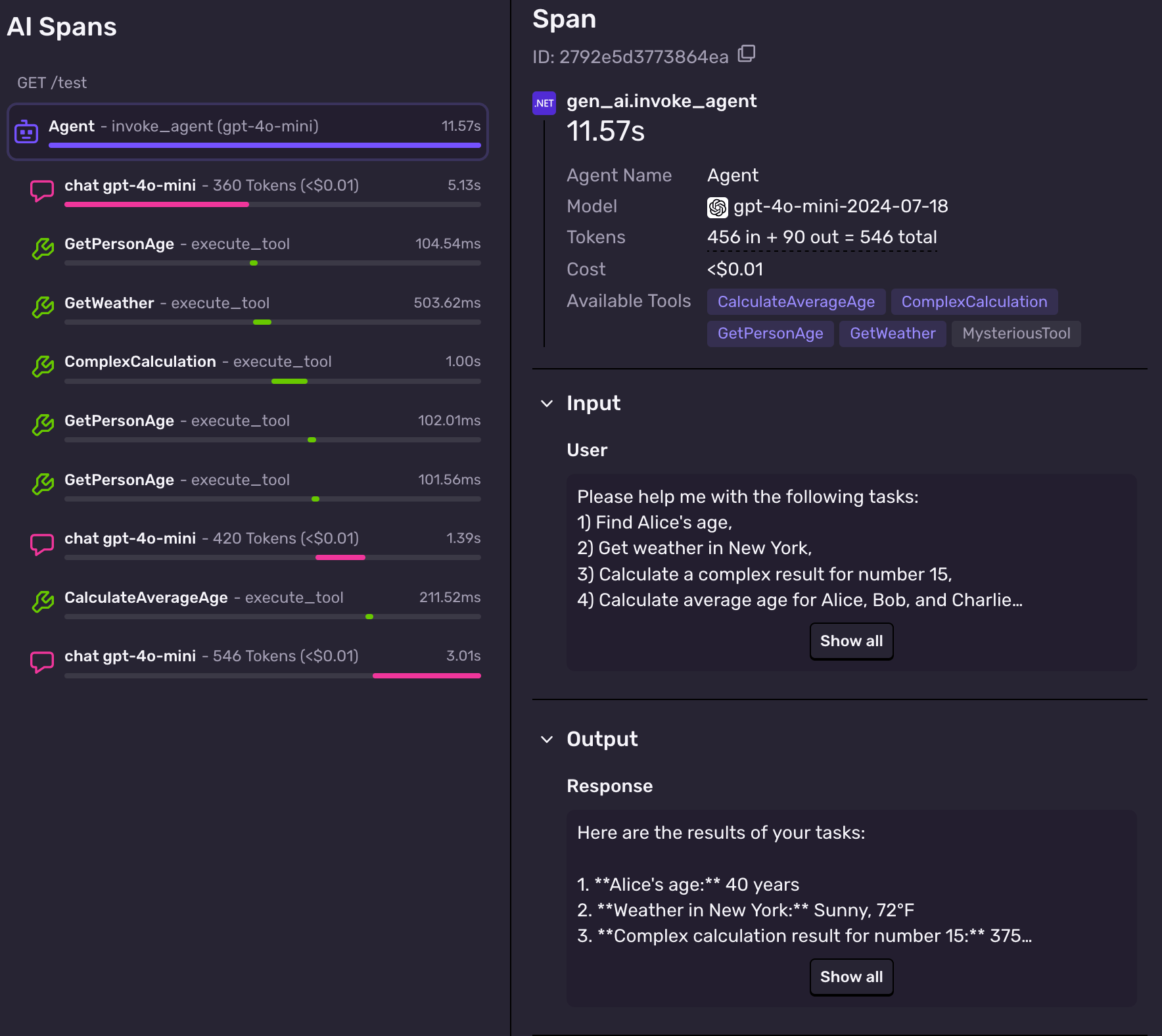
The agent span shows the duration of the whole LLM interaction, including any tool calls and text generation. It also contains the original input and the final output.
When you use the FunctionInvokingChatClient — or UseFunctionInvocation — from Microsoft.Extensions.AI, the LLM call flow looks roughly like this:
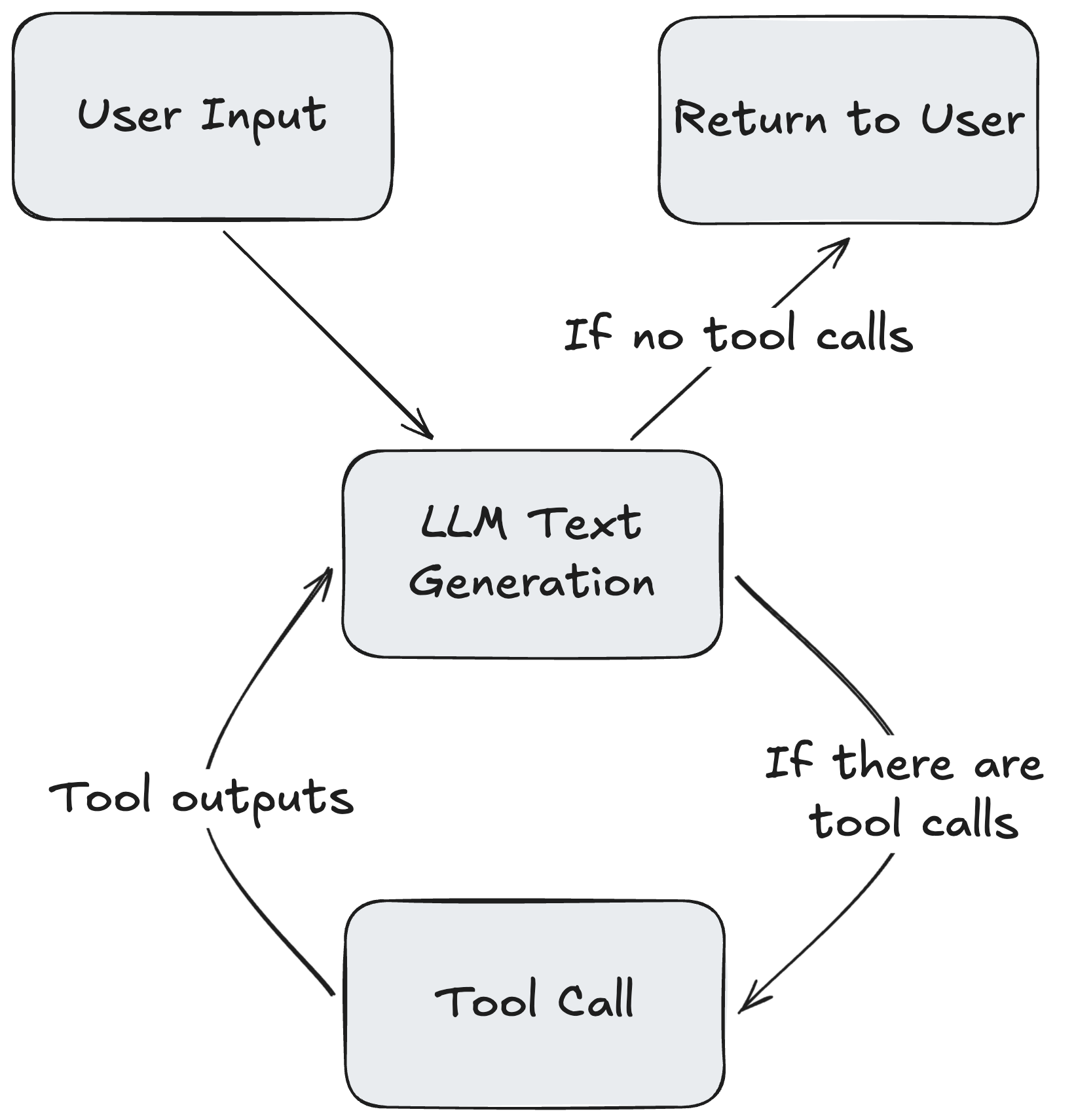
We wanted one span that covered this entire loop. From the first LLM call, through all tool calls, to the final response. The problem was FunctionInvokingChatClient lives in Microsoft.Extensions.AI, not in Microsoft.Extensions.AI.Abstractions, and my instrumentation is built around the abstractions layer. There was no obvious hook at the “whole loop” level.
The workaround was to piggyback on FunctionInvokingChatClient's existing telemetry:
FunctionInvokingChatClientstarts anActivitywhen its tool-call loop begins and stops it when the loop finishes.We created an
ActivityListenerthat taps into theActivity, with itsActivityStartedandActivityStoppedcallback functions set to create Sentry spans.Inside that span, we still record the individual LLM calls and tool calls as child spans.
This gives us exactly what we wanted. A single top-level span that represents the full agent/tool orchestration, without needing direct access to FunctionInvokingChatClient from the abstractions layer.
Future of Agent Monitoring in .NET
Because Microsoft.Extensions.AI.Abstractions sits at the base of many AI libraries, this integration is just the beginning.
Microsoft’s new agent framework, Microsoft.Agents.AI, builds on these abstractions, and so do other higher-level frameworks like Semantic Kernel. That means the same concepts we use today for instrumenting raw IChatClient calls can be extended to:
Track multi-step agent workflows
Visualize tool and plugin orchestration
Add observability to Semantic Kernel pipelines, planners, and skills
Our goal is for Sentry.Extensions.AI to become the standard way to monitor .NET AI workloads — whether you’re calling a single model directly or orchestrating complex agentic systems on top of Microsoft.Extensions.AI.Abstractions.