Fixing Python Performance with Rust
Fixing Python Performance with Rust

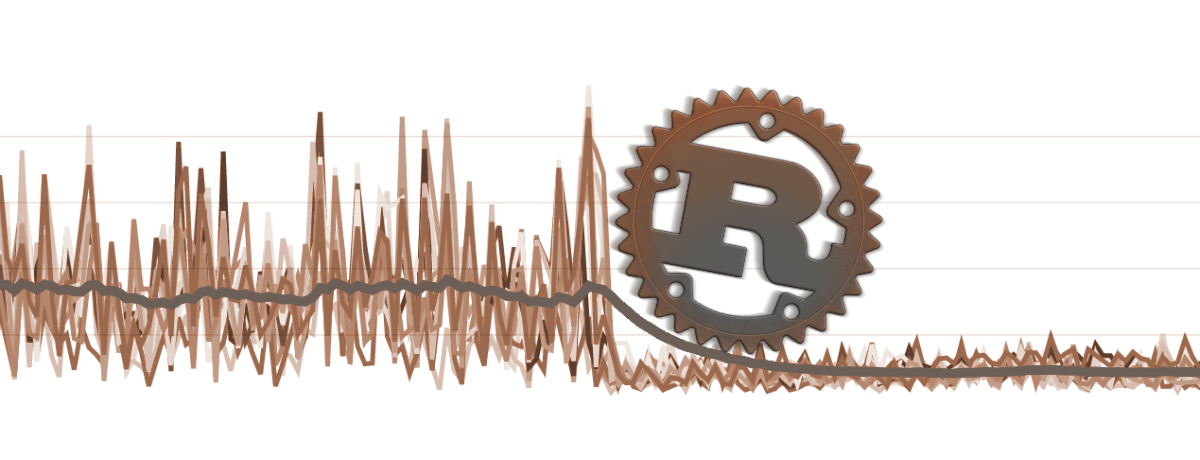
Sentry processes billions of errors every month. We've been able to scale most of our systems, but in the last few months, one component has stood out as a computational chokepoint: Python's source map processing.
Starting last week, the infrastructure team decided to investigate the scaling shortcomings of our source map processing. Our Javascript client has jumped to become our most popular integration, and one of the reasons is our ability to un-minify JavaScript via Source Maps. Processing does not come operationally free, though. We have to fetch, de-compress, un-minify, and reverse transpile our way into making a JavaScript stack trace legible.
When we had written the original processing pipeline almost 4 years ago, the source map ecosystem was just starting to come to fruition. As it grew into what is now a complex and mature mapping process, so did our time to process them in Python.
As of yesterday, we have dramatically cut down that processing time (and CPU utilization on our machines) by replacing our source map handling with a Rust module that we interface with from Python.
To explain how we got here, we first need to better explain source maps and their shortcomings in Python.
Source Maps in Python
As our user’s applications are becoming more and more complex, so are their source maps. Parsing the JSON itself is fast enough in Python, as they mostly contain just a few strings. The problem lies in objectification. Each source map token yields a single Python object, and we had some source maps that expanded to a few million tokens.
The problem with objectifying source map tokens is that we pay an enormous price for a base Python object, just to get a few bytes from a token. Additionally, all these objects engage in reference counting and garbage collection, which contributes even further to the overhead. Handling a 30MB source map makes a single Python process expand to ~800MB in memory, executing millions of memory allocations and keeping the garbage collector very busy with tokens’ short-lived nature.
Since this objectification requires object headers and garbage collection mechanisms, we had very little room for actual processing improvement inside of Python.
Source Maps in Rust
After the investigation had pointed us towards Python’s shortcomings, we decided to vet the performance of our Rust source map parser, perviously written for our CLI tool. After applying the parser to a particularly problematic source map, it showed that parsing with this library alone could cut down the processing time from >20 seconds to <0.5 sec. This meant that even ignoring any optimizations, just replacing Python with Rust could relieve our chokepoint.
Once we proved that Rust was definitively faster, we cleaned up some Sentry internal APIs so that we could replace our original implementation with a new library. That Python library is named libsourcemap and is a thin wrapper around our own rust-sourcemap.
The Results
After deploying the library, the machines that were dedicated to source map processing instantly sighed in relief.

With all of the CPUs efficiently processing, our worst source map times diminished to a tenth of their original time.

More importantly, the slowest times were not the only maps to receive improvements. The average processing time reduced to ~400ms.

Since JavaScript error tracking is our most popular project, this change reached as far as reducing the end-to-end processing time for all events to ~300ms.

Embedding Rust in Python
There are various methods to expose a Rust library to Python and the other way round. We chose to compile our crate into a dylib and to provide some good ol’ C functions, exposed to Python through CFFI and C headers. With the headers, CFFI generates a tiny shim that can call out into Rust. From there, libsourcemap can open a dynamically shared library that is generated from Rust at runtime.
There are two steps to this process. The first is a build module that configures CFFI when setup.py runs:
import subprocess
from cffi import FFI
ffi = FFI()
ffi.cdef(subprocess.Popen([
'cc', '-E', 'include/libsourcemap.h'],
stdout=subprocess.PIPE).communicate()[0])
ffi.set_source('libsourcemap._sourcemapnative', None)After building the module, the header is ran through the C preprocessor so that it expands macros, a process that CFFI cannot do by itself. Additionally, this tells CFFI where to put the generated shim module. All that needs to happen after that is loading the module:
import os
from libsourcemap._sourcemapnative import ffi as _ffi
_lib = _ffi.dlopen(os.path.join(os.path.dirname(__file__), '_libsourcemap.so'))The next step is to write some wrapper code to provide a Python API to the Rust objects, and since we’re Sentry, we started with the ability to forward exceptions. This happens in a two-part process: First, we made sure that in Rust, we used result objects wherever possible. In addition, we set up landing pads for panics to make sure they never cross a DLL boundary. Second, we defined a helper struct that can store error information; and passed it as an out parameter to functions that can fail.
In Python, a helper context manager was provided:
@contextmanager
def capture_err():
err = _ffi.new('lsm_error_t *')
def check(rv):
if rv:
return rv
try:
cls = special_errors.get(err[0].code, SourceMapError)
exc = cls(_ffi.string(err[0].message).decode('utf-8', 'replace'))
finally:
_lib.lsm_buffer_free(err[0].message)
raise exc
yield err, checkWe have a dictionary of specific error classes (special_errors) but if no specific error can be found, a generic SourceMapError will be raised.
From there, we can actually define the base class for a source map:
class View(object):
@staticmethod
def from_json(buffer):
buffer = to_bytes(buffer)
with capture_err() as (err_out, check):
return View._from_ptr(check(_lib.lsm_view_from_json(
buffer, len(buffer), err_out)))
@staticmethod
def _from_ptr(ptr):
rv = object.__new__(View)
rv._ptr = ptr
return rv
def __del__(self):
if self._ptr:
_lib.lsm_view_free(self._ptr)
self._ptr = NoneExposing a C ABI in Rust
We start with a C header containing some exported functions, but how can we export them from Rust? There are two tools: the special #[no_mangle] attribute, and the std::panic module providing a landing pad for Rust panics. We built ourselves some helpers to deal with this: a function to notify Python about an exception and two landing pad helpers: a generic one and one that boxes up the return value. With this, it becomes quite nice to write wrapper methods:
#[no_mangle]
pub unsafe extern "C" fn lsm_view_from_json(
bytes: *const u8, len: c_uint, err_out: *mut CError) -> *mut View
{
boxed_landingpad(|| {
View::json_from_slice(slice::from_raw_parts(bytes, len as usize))
}, err_out)
}
#[no_mangle]
pub unsafe extern "C" fn lsm_view_free(view: *mut View) {
if !view.is_null() {
Box::from_raw(view);
}
}The way boxed_landingpad works is quite simple. It invokes the closure, catches the panic with panic::catch_unwind, unwraps the result and boxes up the success value in a raw pointer. In case an error happens it fills out err_out and returns a NULL pointer. In lsm_view_free, one just has to reconstruct the box from the raw pointer.
Building the Extension
To actually build the extension, we have to run some less-than-beautiful steps inside of setuptools.
Thankfully, it did not take us much time to write it since we already had a similar set of steps for our DSYM handling library.
The handy part of this setup is that a source distribution invokes cargo for building, and binary wheels for installing the final dylib, removing the need for any end-user to navigate the Rust toolchain.
What went well? What didn’t?
I was asked on Twitter: “what alternatives to Rust there would have been?” Truth be told, Rust is pretty hard to replace for this. The reason is that, unless you want to fully rewrite an entire Python component in a different codebase, you can only write a native extension. In that case, your requirements to the language are pretty harsh: it must not have an invasive runtime, must not have a GC, and must support the C ABI. Right now, the only languages I think that fit this are C, C++, and Rust.
What worked well:
Marrying Rust and Python with CFFI. There are some alternatives to this which link against libpython, but it makes for a significantly more complex wheels build.
Using ancient CentOS versions to build somewhat portable Linux wheels with Docker. While this process is tedious, the difference in stability between different Linux flavors and kernels make Docker and CentOS an acceptable build solution.
The Rust ecosystem. We're using
serdefor deserialization and a base64 module from crates.io, both working really well together. In addition, the mmap support uses another crate that was provided by the community memmap.
What didn’t work well:
Iteration and compilation times really could be better. We are compiling modules and headers every time we change a character.
The setuptools steps are very brittle. We probably spent more time making setuptools work than any other developmental roadblock that came up. Luckily, we did this once before so it was easier this time around.
While Rust is pretty great for what we do, without a doubt there is a lots that needs to improve. In particular, the infrastructure for exporting C ABIs (and to make them useful for Python) could use lots of improvements. Compile times are also not great at all. Hopefully incremental compilation will help there.
Next Steps
There is even more room for us to improve on this if we want. Instead of parsing the JSON, we can start caching in a more efficient format, which is a bunch of structs stored in memory. In particular, if paired with a file system cache, we could almost entirely eliminate the cost of loading since we bisect the index, and that can be done quite efficiently with mmap.
Given the good results of this we will most likely evaluate Rust more in the future to handle some expensive code paths that are common. However there are no CPU-bound fruits that current hang lower than source maps. For most of our other operations, we’re spending more time waiting for IO.
In Summary
This project has been a tremendous success. It took us very little time to implement, it lowered processing times for our users, and it also will help us scale horizontally. Rust has been the perfect tool for this job because it allowed us to offload an expensive operation into a native library without having to use C or C++, which would not be well suited for a task of this complexity. While it was very easy to write a source map parser in Rust, it would have been considerably less fun and more work in C or C++.
We love Python and Python error tracking at Sentry, and we're proud contributors to numerous Python open-source initiatives. While Python remains our favorite go-to, we believe in using the right tool for the job, no matter what language it may be. Rust proved to be the best tool for this job, and we are excited to see where Rust and Python will take us in the future. If you feel the same way, we’re hiring in multiple positions and would love to hear from you.


