Treat Performance Like A Feature
Treat Performance Like A Feature


I, like many of you no doubt reading this, am an engineer with very strong opinions on how software should work. I am not interested in moving fast and breaking things; I am not interested in changing the world. I am interested in building pleasant, ergonomic software and charging money for it.
My company, Buttondown, was born from that ethos. Buttondown is a tool for sending emails and newsletters — and though many newsletter tools exist, Buttondown is meant to be a more minimalist, developer-friendly experience that prioritizes programmatic access and accessibility and performance over feature bloat.
And yet…application performance deteriorates over time
Abstract principles sound nice, but anyone in charge of triaging a roadmap knows that the road to performance hell is paved with good intentions.
And so my performance work would often fall into two buckets:
When a new feature launches, it is launched as cleanly and properly as possible — strict tests on the number of database calls for every API route, load testing, the whole nine yards.
If someone files a bug report about a very slow endpoint (or — god forbid — I get an exception about a timeout!) I dutifully handle it as a discrete ticket.
This is easy, legible work. This is testable work. It also ignores how performance actually degrades over time: slowly, quietly, with an extra loop here and a poorly-optimized database call there, a series of barely-visible erosions that you discover only once you receive an email from a customer who churned because “the core flows just don’t feel quite as snappy as they should.”
But it also doesn’t result in a good, performant application. Core flows — say, saving a draft or listing all emails that you’ve published — would increase over time from taking full milliseconds. Emails would go out slower than they used to, leading users to wonder if they mis-sent something. Bounce rates would increase. Things looked ‘fine’ because nothing was crashing — but the app was getting worse.
Shifting performance from abstract to actionable
I had been using Sentry for a long time for the same reason most people do — issue reporting. Their lightweight interface and quick installation process made it easy for me to process, triage, and resolve issues in the same way I do everything else — keeping a clean inbox zero.
I was a little skeptical when I saw they were expanding their reach into performance and other ancillary functions. I am not in the habit of adding more ambient information to keep an eye on: the idea of having a scorecard of unactionable information to browse through every Monday morning alongside my metrics deck felt just like a grim reminder that there was only so much time left in the day.
That skepticism vanished once I started understanding what specifically Sentry was offering: a legibility layer for performance. These were not abstract line graphs that offered more open questions (“is this a degradation, or is this table just getting bigger?”) than answers. They were discrete and solvable issues.
Take this N+1 error notification that let me speed up an onboarding-sensitive route in all of two lines in Python:
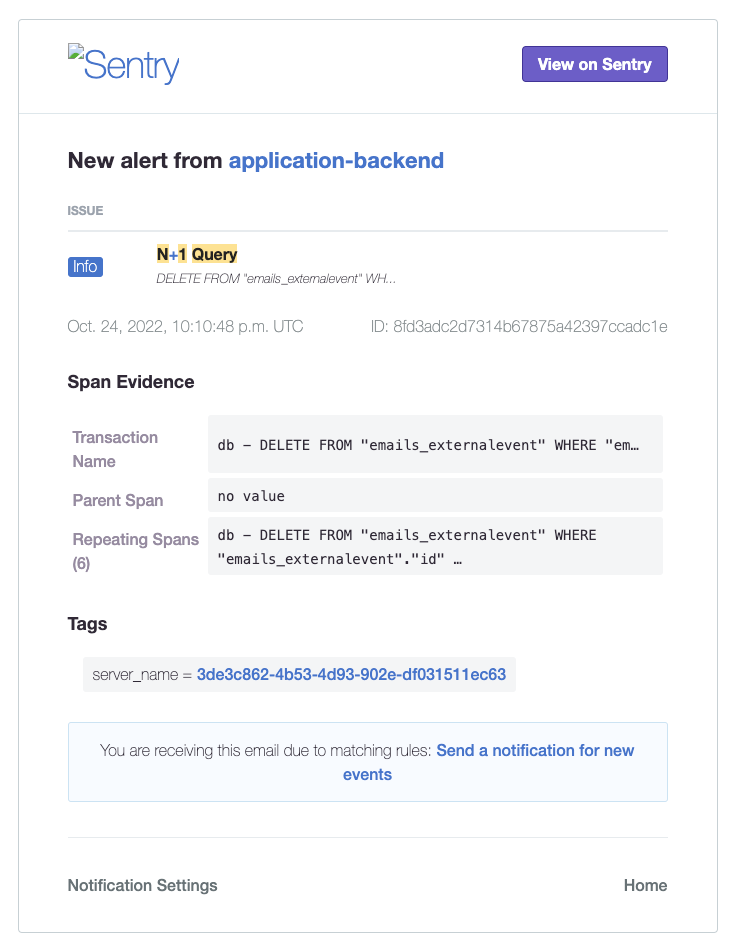
Or this surfacing of a slow DB operation to let me double the speed at which outgoing emails are rendering and sent:
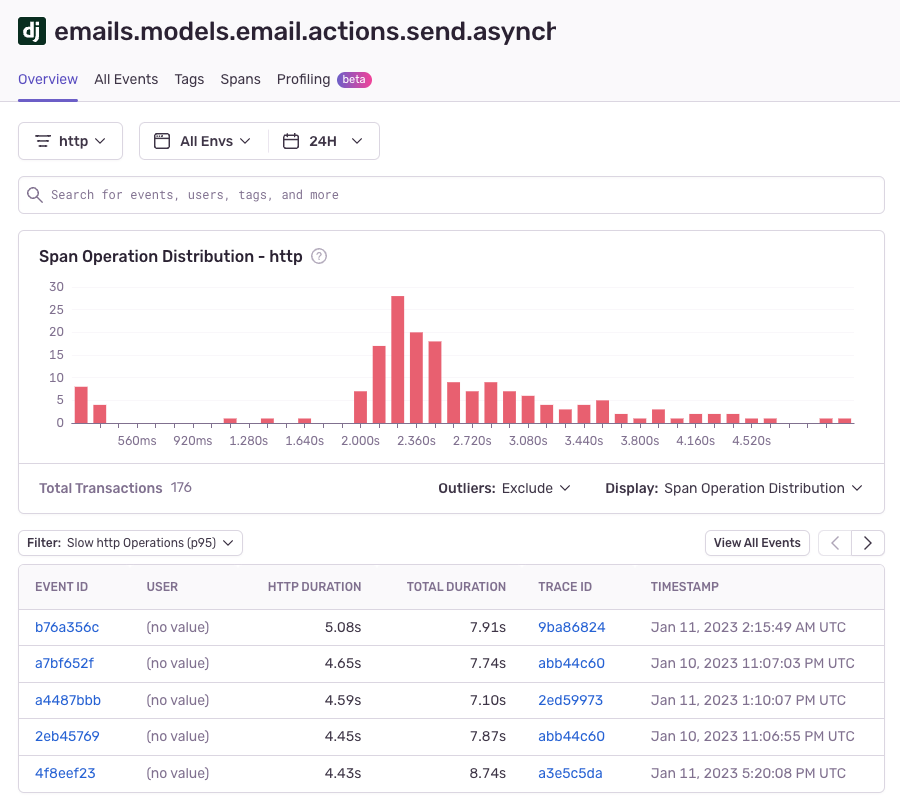
All of these items transformed a vague, qualitative problem (“performance has gone down over time!”) into a rigid, quantitative one (“these eight routes have performed much worse over the past twelve months!”). Now I prioritize performance work at the same level of understanding and granularity as any other part of Buttondown.
Why performance matters for developers
I think there’s a tendency to treat application performance concerns as, for lack of a better word, cute — a genre of problems perpetually consigned to the “nice to have” bucket when doing sprint planning or carving out a quarterly roadmap. I understand this perspective. There have been very few customer deals I’ve lost because a prospect complained about the p95 performance of one of my pages, and there are quite a few I can point to having lost because I didn’t have a given feature.
But users — especially technical users — care. They care a lot, and they notice, even in ways that they’re unable to vocalize or internalize. I remember vividly an onboarding call I had with a logo customer a few months after they had started using Buttondown:
I’m not sure what you’ve done with [the subscriber management interface], but it feels much easier to navigate through and filter. Nice job improving the UX here.
The UX, dear reader, had not changed a single pixel. What changed was the speed — I had, thanks to Sentry, turned a bunch of filters and explorations from a troublesome five-second feedback loop into a <1 second playground.
Buttondown is not going to gain users on the back of its excellent sales team (we don’t have one) nor its ability to churn out features (it’s hard to win an arms race). Buttondown will continue to gain — and keep — users on its sheer ease of use, and Sentry makes that much easier.
One part product, one part process: A recommendation for how to think about your application performance
Anecdotes and positive thinking about the abstract importance of well-performing software is gratifying; it is not, however, particularly useful when you are a beleaguered engineer trying to advocate for performance investments and being shot down by a product manager who has a two-hundred-item-long JIRA backlog.
To that end, I have a recommended process for engineers interested in rigorously prioritizing and improving performance issues. This worked when I was an engineer at Amazon and Stripe and it still defines how I think about performance, even when I’m wearing both the ‘engineer’ and the ‘product manager’ hat:
Transform abstract woes into concrete issues. “This needs to be faster” is just as vacuous as “this feature should exist.” Use tools like Sentry’s performance dashboard to be specific and actionable — explain which systems are slow, what slow is, and how you measure slowness. The goal with performance work — just like any work — is to have a sense of falsifiability and an understanding of what acceptance criteria might be.
Define and contextualize user pain. Explain why performance matters for the specific issue. Is it a core flow impacting a primary job-to-be-done for your application’s users? What percentage of active users feel this pain?
Elevate from ad-hoc decision-making to contractual obligation. Once the work is deemed as net-useful, set up processes and tests (e.g., checkers, Sentry dashboards, regression tests) to make sure the problem does not recur. This helps build a culture of performance being just another part of healthy software – you wouldn’t feel good about a route returning 500s 10% of the time, so why would you feel good about a route taking five seconds to resolve 10% of the time?
Best of luck — may your software be faster tomorrow than it was today. (Buttondown’s not quite as fast as it should be, but it’s faster than it was last month — and that’s a trend in the right direction.)


