I turned error messages into a sales machine (by accident)
I turned error messages into a sales machine (by accident)


ON THIS PAGE
- How it started
- Turning errors into leads
- Known errors are actually not that scary
- Tackling the most common error
- How it's going
- Final thoughts
Dan Mindru is a Frontend Developer and Designer who is also the co-host of the Morning Maker Show. Dan is currently developing a number of applications including PageUI, Clobbr, and CronTool.
I find it remarkable that we’re getting so many AI startups every day.
As software engineers, most of us like to know what our software is actually doing. We plan, review, and perform automatic tests to verify it’s working as expected. Then we do a round of manual testing for good measure. Not with AI.
After months and months of testing, I found myself in an uncomfortable position. My startup mostly worked, except for when it completely failed to do the task.
Indeed, about 90% of the time it did work. However, getting from 0 to 80% took 1 month, then 80% to 90% took 3 months, and it seemed 90% to 100% will take at least 12 months.
At the current pace, 12 months in “AI time” is equal to about a century of regular time, so I immediately understood why we’ve been getting so many startups every day.
They launch now anyway 🤷♂️
12.000 users later, let me explain how this worked out as an advantage for me. Plus, you’ll never guess what our biggest issue was!
How it started
I wanted to create a startup that revolutionizes building websites. PageAI is a website builder that can plan, design and code an entire production website from a simple description. It sounds quite spectacular, and so were the errors!
As you can imagine, many things could (and did) go wrong. We didn’t know all ways it could go wrong, but we knew we couldn’t trust the AI output. Not only from a security perspective, but also when considering design or code quality.
So we needed to accept it will go wrong and be good at handling it.
A classic chicken and egg problem. If we don’t get it into the hands of a ton of people, we won’t find out all the ways it can fail. On the flip side, if we try to discover those ourselves, we’ll run out of funding and risk releasing an obsolete product (PageAI is bootstrapped by the way, so there was also a hard limit on scaling QA).
So we did what everybody else did. We launched anyway.
But wait, I am not that eccentric. Before launching, we tried to fence AI errors and mitigate them to the best of our abilities. Some of the things we did:
wrote our own parser, so the generated code was parsed and then “rebuilt” by us, skipping all the dubious/dangerous output
hardened prompts, checks and agentic flows to safeguard outputs
added extra handling + sandboxing in the front-end to prevent crashes
The launch went great by all measures, we got our first 2000 users within a week.
However, it was dead quiet. Nobody complained. Something wasn’t right as we expected at least 1 in 10 to have issues. This was our first problem.
❌ Problem #1: we couldn’t see how bad it was
Even though we could see exceptions happening, users didn’t want to put in the effort to report them. They tried it, got an error, and moved on to a competitor. Not good.
✅ Solution #1: add easy ratings
A quick fix for this was to add a rating widget right next to the publish button. This was low effort and in your face, so many started to interact with it.
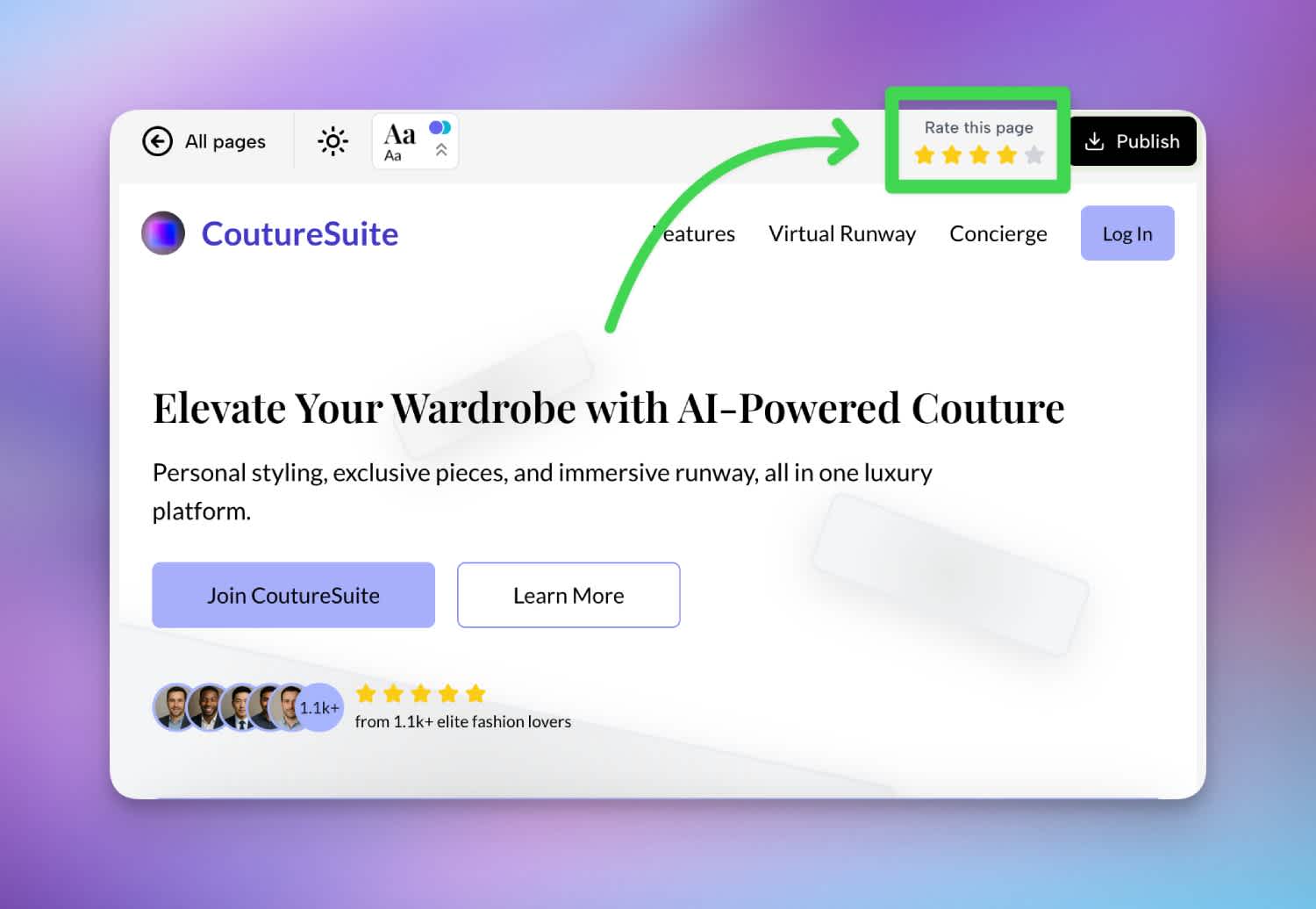
Rating widget added in PageAI’s top bar.
Reviews started to come in, and just as expected, there were quite a few 1-star ratings.
Still, almost nobody was reaching out to us.
❌ Problem #2: it was too hard to give feedback
Beyond hitting the star rating, people didn’t go to the contact page and email us. Because of that, they were not “invested” in solving the problem and again, tried out a competitor.
✅ Solution #2: add a feedback widget on page
This was easy: enable the Sentry feedback widget.
Great! Now users finally find it easy enough to send us feedback. You can probably see the next issue…
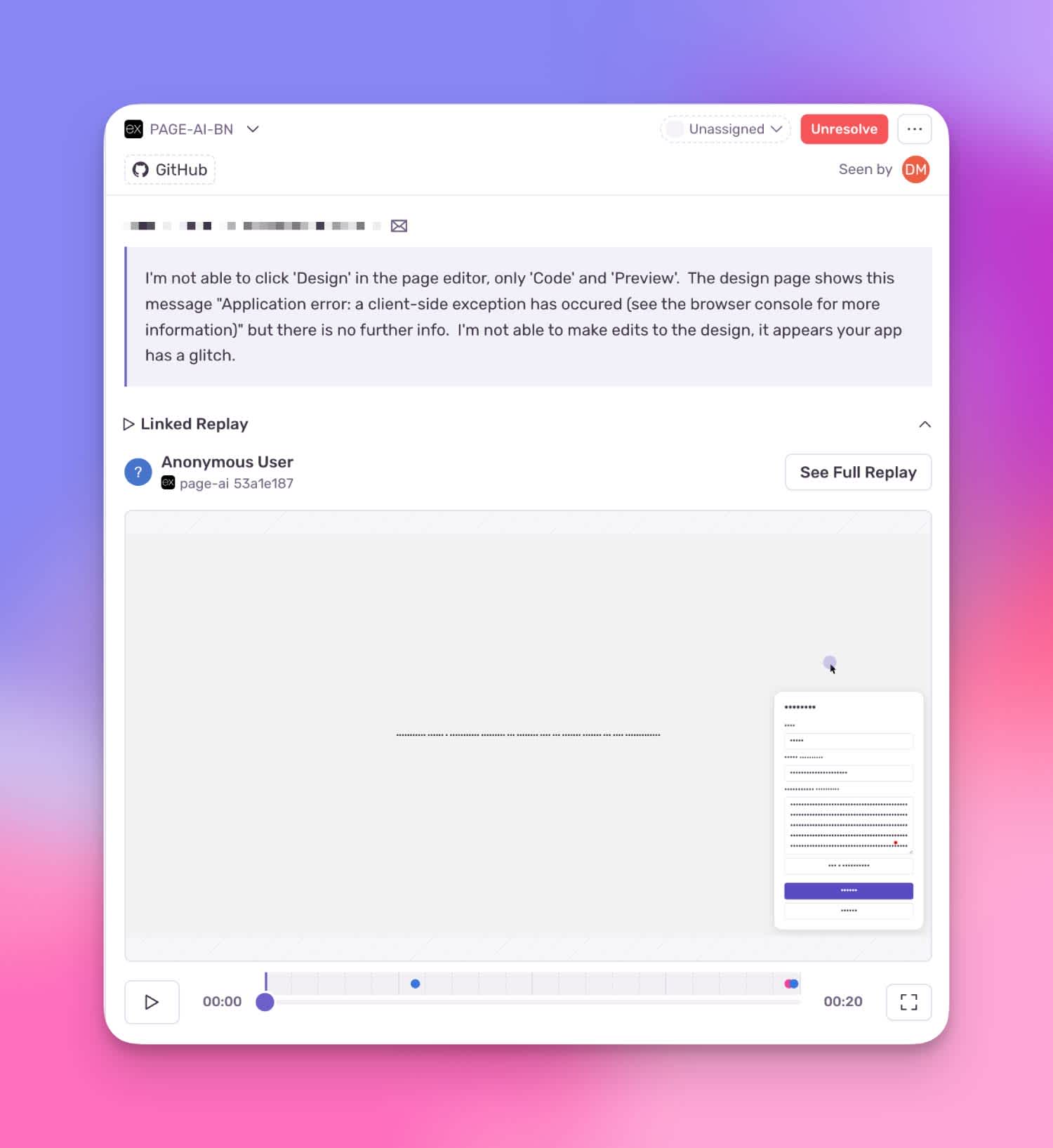
User sending feedback with an error
❌ Problem #3: generic errors took too long to fix and react to
Our mitigation strategies only captured back-end errors, but the front-end was a complete blackbox. “A client-side exception has occurred” could mean anything. Because of that, we weren’t fast enough to react and customers moved on.
✅ Solution #3: better traces & a tiny, magical UI change
We needed to capture & forward the full client error to the Sentry trace.
That allowed us to react and fix issues a lot faster. That gave us confidence and gave us this idea: what if we’d add a “Trying to autofix” spinner, would users stick around more?
This tiny UI element turned everything around for us.
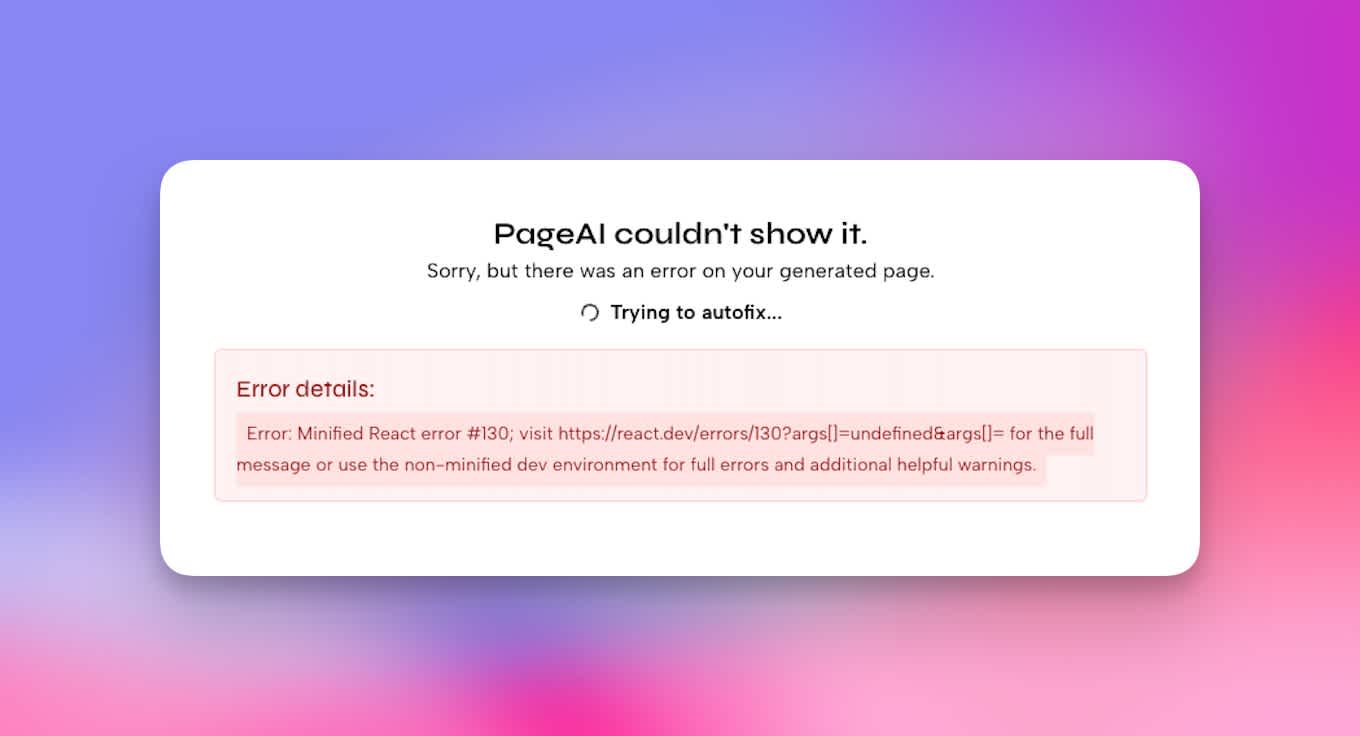
An error with the “Trying to autofix” spinner
Turning errors into leads
In a past podcast episode, we had the pleasure to talk with John Rush, founder of over 24 startups (some doing millions in recurring revenue!). He had to say this on the topic:
“It’s not a good idea to make you product perfect. You have to create a reason for people to message you. Every product that I have, every landing page that I have, has spelling mistakes. I am not afraid of having bugs because they bring people into our chat […], then the way you respond will earn those people’s trust. They’ll feel comfortable to send feedback and know they can count on you”
You see, having the “Trying to autofix” spinner did 3 things for our users:
they stuck around for longer
they messaged us more often
they trusted us and were impressed by our support
For some reason, it was a lot easier for them to write “Your autofix is stuck, can you take a look”.
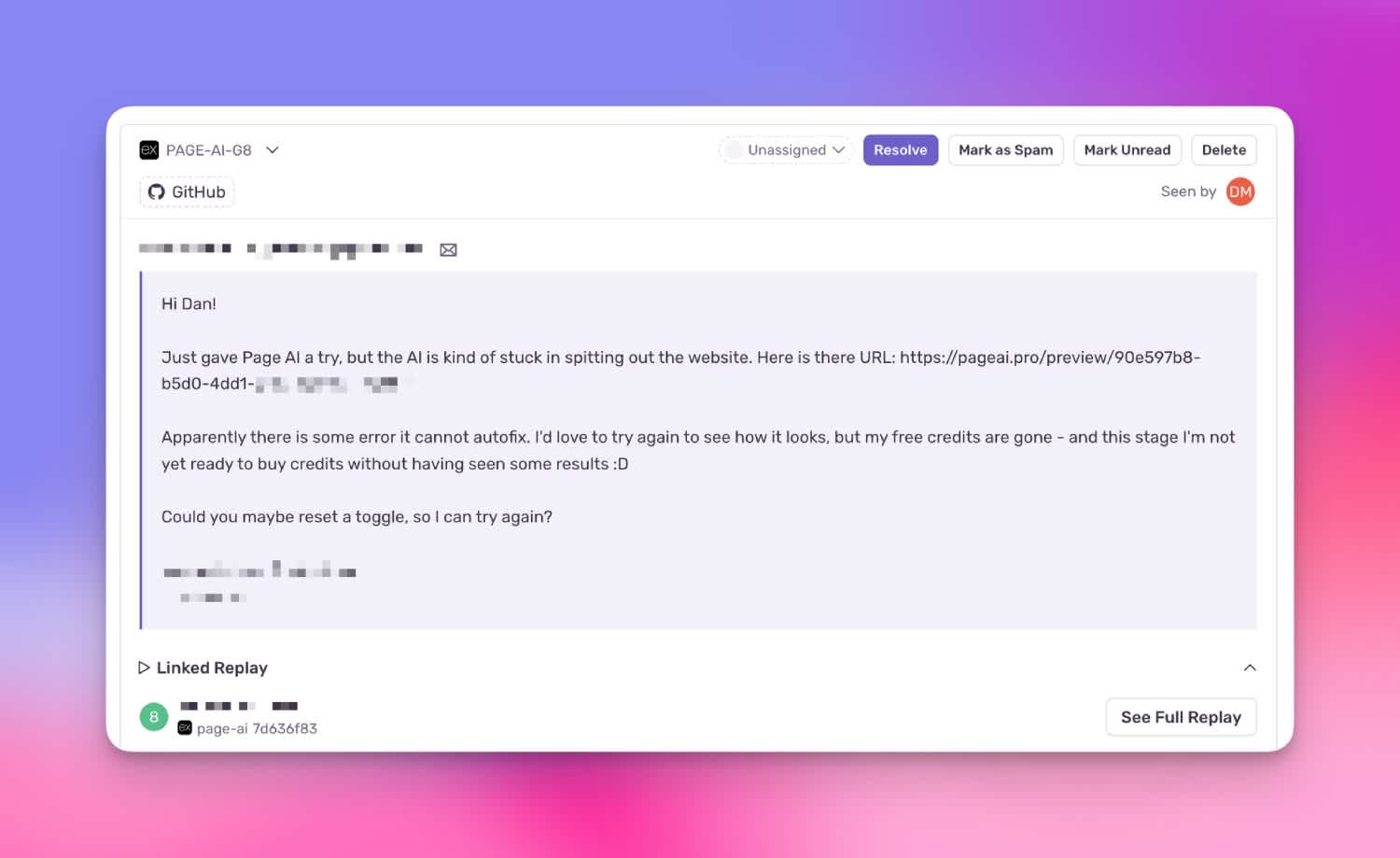
User reaching out with autofix issue
Every Sentry notification was basically a sales lead in disguise.
Due to the improved tracing, most of these errors were trivial to fix. An unescaped string, a missing import, an unclosed element.
In fact, our support became so efficient that we’d immediately reply with “the issue has been fixed”, or in some cases, they noticed the fix before we even replied.
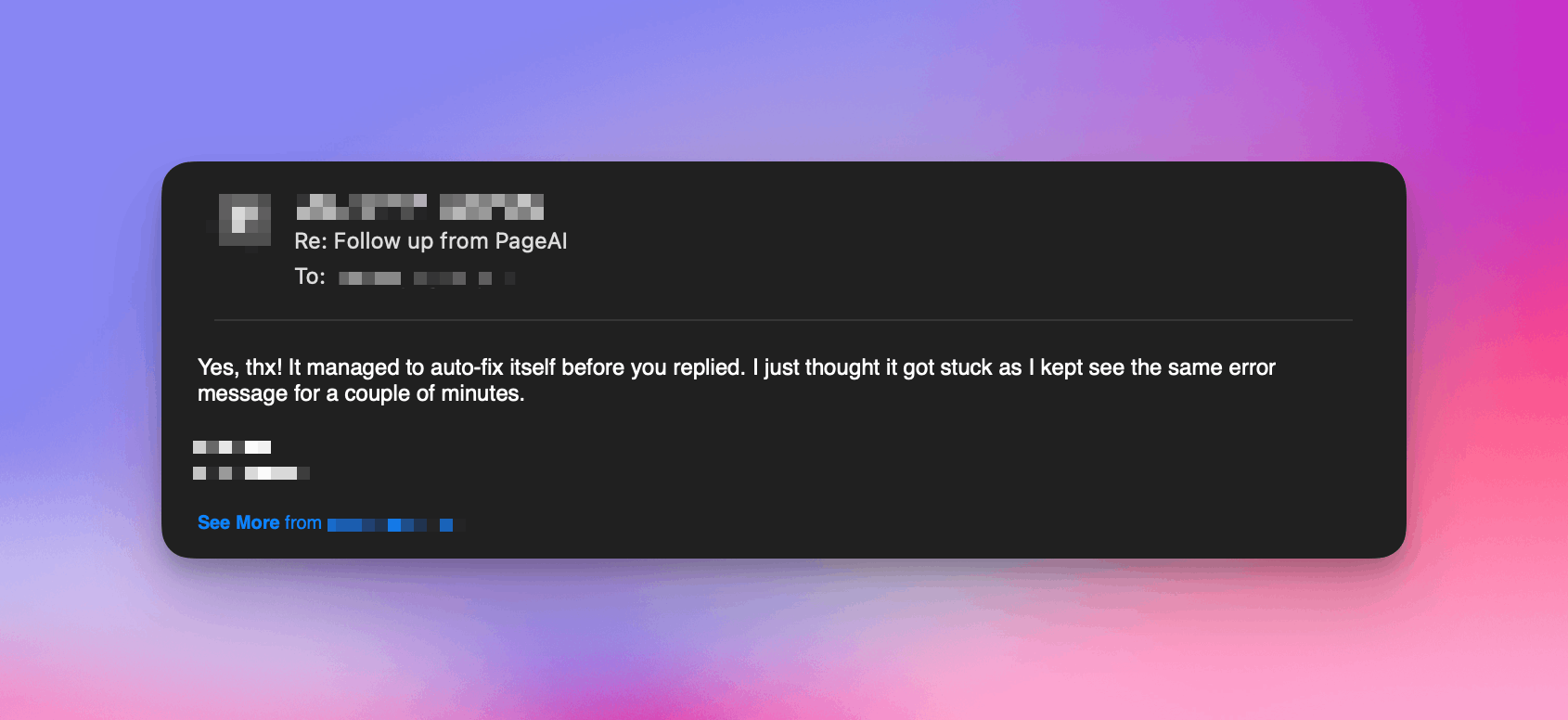
User thinking their issue was autofixed
Funnily enough, this was often quicker than AI itself could “autofix”, albeit not as scalable.
Here is the kicker: most were so blown away by this level of support that they actually ended up purchasing the product. Usually within a few hours from sending their feedback.

User purchasing product hours after sending feedback
Turns out, users trust you even when things break if you manage to fix them fast enough.
Don’t get me wrong, we wanted the autofix to actually work, but throwing more AI at the problem felt like a band-aid solution. Plus, it would cost more and be a lot slower.
What we really wanted is to find patterns and hopefully leverage Seer AI to find fixes to root causes.
And so we turned a stressful affair into a fun exercise.
Known errors are actually not that scary
Allow me to bring up this age-old cliché.
In software, there are known knowns, known unknowns, and the most terrifying ones: unknown unknowns. The latter are the ones that keep me up at night.
In an AI-heavy application, there can be heaps of unknown unknowns. The best we can do is to mitigate them. Let me give you an example in context.
So when a user prompts “Create a website for a logging app”, what we don’t want is:
❌ PageAI outputs “demo code” that logs every keystroke including passwords and credit cards to a remote storage bucket.
What we do want is:
✅ PageAI outputs a landing page showcasing a log management app
Our job was to fence the AI so we eliminate the unknown unknowns. Once that’s done, the errors are a lot more manageable:
A missing import
An ugly section
A syntax error that prevents the landing page from rendering
And for all the rest, we have Sentry.
Bugs are good if you squash them in front of the user.
They are not ideal, but we can work with that. Consider them your friendly neighborhood errors.
In fact, I don’t recommend fixing them right away. Here’s why:
new models come out all the time, they might fix them for you
you might pivot/remove the feature based on user feedback
the architecture might be wrong, so you’re approaching this at the wrong end
you get to actually talk to your users and understand their needs and frustrations
But I promised you I’ll share our most common error. It’s really not what you expect.
Tackling the most common error
You’d think that in the era of GPT-5 and Claude Opus 4.1, we’d be past silly hallucinations.
Well, think again.
As you might have noticed, AI is really good at doing things by example. Some of our prompts contained examples of icons, and so AI filled in the gaps and started to use its own icons that, obviously, didn’t exist. Here’s what most of our errors looked like:
Example of a common icon hallucination
Ah yes, “working like a clock” indeed.
We tried everything:
Make it write SVGs from scratch
Fed it a limited, complete list of icons
Having a review agent to fix icons
None of these did much, except for increasing cost and decreasing performance. Obviously, when you see AI as a hammer, every problem becomes a nail.
Ultimately, we had to take a step back and make a good old-fashioned regex parser that replaces missing icons with generic fallbacks. And so our most common error was fixed.
How it's going
As we got wiser on the type of errors, we ended up re-writing our AI code output parser. It became more forgiving, and gracefully handled the parts that failed without crashing the entire generated website. Later, PageAI also got drag and drop editing capabilities, so users could fix many of those errors themselves.
In the end, the autofix feature was not necessary anymore.
PageAI grew to 12000 users and counting, so the approach definitely paid off.
Final thoughts
Thinking more broadly, is this an approach everyone should try? I’ve worked in many industries as a consultant and one thing was universally true:
Customers value support.
I by no means suggest introducing new bugs just to talk to users. What I am suggesting is containing unknowns to understand how important they actually are to your users. Are they more important than the next feature you’re working on?
If that still sounds terrifying to you, consider rolling out betas that way. Oftentimes we over-engineer things that users don’t care about. Or we make things perfect only to completely change them in the next release.
Remember, perfect is the enemy of good, and for the rest?
For the rest we have Sentry.


